## 1.1 二手房分析
```
import pandas as pd
# 读取Excel文件
df = pd.read_excel("xihu.xlsx")
def processName(x):
return x.strip("['']")
#数据清洗
df['小区名称'] = df['小区名称'].apply(processName)
df['建筑面积'] = df['建筑面积'].str.replace('㎡', '').astype(float)
#任务1:小王有200万买房预算,想买一个建筑面积80平米以上,一梯两户,附近有学校的房子,请帮他筛选出来?
def contains_school(x):
words = ["学校", "大学", "中学", "小学"]
for word in words:
if word in str(x):
return True
return False
xiaowang_df=df[(df['建筑面积'] > 80) & (df['梯户比例'] == '一梯两户')&
(df["小区介绍"].apply(contains_school)|df["核心卖点"].apply(contains_school))]
# 任务2:公司董事长请你帮忙挑选出西湖区最高档的小区(单价最贵)
average_prices_per_area = df.groupby('区域位置')['单价'].mean()
# 按照平均房价降序排序
sorted_prices = average_prices_per_area.sort_values(ascending=False)
sorted_prices.index[0]
# 任务3 识别炒房
# 转换日期列为datetime对象
df['上次交易'] = pd.to_datetime(df['上次交易'])
df['挂牌时间'] = pd.to_datetime(df['挂牌时间'])
# 计算日期差异(以年为单位)
df['交易与挂牌时间差'] = (df['挂牌时间'] - df['上次交易']) / pd.Timedelta(days=365)
# 筛选条件:面积小于100平米,且交易与挂牌时间差小于5年
filtered_df = df[(df['建筑面积'] < 100) & (df['交易与挂牌时间差'] < 5)]
```
## 2.新浪股票分析
### 可视化
```python
import pandas as pd
import matplotlib.pyplot as plt
# 定义列名
column_names = ['股票代码', '交易日期', '收盘价', '最高价', '最低价', '开盘价', '前收盘', '涨跌额', '涨跌幅', '换手率', '成交量', '成交金额', '总市值', '流通市值']
# 读取CSV文件,指定列名
df = pd.read_csv('stock.csv',names=column_names)
# 数据预处理,将交易日期转换为日期时间对象
df['交易日期'] = pd.to_datetime(df['交易日期'])
# 可视化收盘价随时间的变化
plt.figure(figsize=(22, 6))
plt.plot(df['交易日期'], df['收盘价'], label='close')
# 可视化最高价和最低价随时间的变化
plt.plot(df['交易日期'], df['最高价'], label='high')
plt.plot(df['交易日期'], df['最低价'], label='low')
# 添加图例
plt.legend()
# 添加标题和轴标签
plt.title('time change')
plt.xlabel('date')
plt.ylabel('price(rmb)')
# 显示图表
plt.show()
# 可视化成交量随时间的变化
plt.figure(figsize=(12, 6))
plt.plot(df['交易日期'], df['成交量'], label='volume')
# 添加标题和轴标签
plt.title('change')
plt.xlabel('date')
plt.ylabel('volume')
# 显示图表
plt.show()
```
```
# 4.3.1 计算收盘价常用统计量
import numpy as np
closing_price = np.loadtxt("stock.csv",
delimiter=",",
usecols=(2))
print("closing_price的类型是:",type(closing_price))
print("closing_price的维数是:",closing_price.shape)
print("closing_price元素个数是:",closing_price.size)
print(closing_price)
avg = np.mean(closing_price)
print("收盘价的平均值是:%.2f" % avg)
med = np.median(closing_price)
print("收盘价的中位数是%.2f" % med)
print("中位数所在位置的索引是:%d" % np.where( closing_price == 23.95 ))
variance =np.var(closing_price)
print("收盘价的方差是:%.2f" % variance)
```
```
# 4.3.2 计算股价最高值和最低值
from numpy import loadtxt
from numpy import max
from numpy import min
from numpy import ptp
(high_price,
low_price) = loadtxt("stock.csv",\
delimiter = ",",\
usecols=(3,4),\
unpack=True)
print("high_price的类型是:",type(high_price))
print("high_price的维数是:",high_price.shape)
print("high_price的元素个数是:",high_price.size)
print("low_price的类型是:",type(low_price))
print("low_price的维数是:",low_price.shape)
print("low_price的元素个数是:",low_price.size)
highest = max(high_price)
print("该股票的股价最高值是:",highest)
lowest = min(low_price)
print("该股票的股价最低值是:",lowest)
middle = (highest + lowest)/2
print("该股票股价的中间值是:",middle)
high_range = ptp(high_price)
print("该股票最高价的波动范围是:",high_range)
low_range = ptp(low_price)
print("该股票最低价的波动范围是:",low_range)
```
## 4.3.3 加权平均价
```
import numpy as np
closing_price = np.loadtxt("stock.csv",\
delimiter = ",",\
usecols = (2),\
unpack=False)
volume = np.loadtxt("stock.csv",\
delimiter = ",",\
usecols = (11),\
unpack=False)
vwap = np.average(closing_price,weights=volume)
print("该股票的成交量加权平均值是:%.2f" % vwap )
t = np.arange(closing_price.shape[0])
twap = np.average(closing_price,weights=t)
print("该股票的时间加权平均值是:%.2f" % twap )
```
## 4.3.4 周末效应
```
import datetime
#年/月/日 ===>星期几
def date2str(nowDate):
nowDate = str(nowDate,"GB2312")
return datetime.datetime.strptime(nowDate,"%Y/%m/%d").date().weekday()+1
days, closing_price = np.loadtxt('stock.csv',\
delimiter = ',',\
usecols = (1,2),\
converters = {1:date2str},\
unpack=True)
for i in range(days.size):
print("发生交易的天数是星期%d,当天收盘价是%f" \
% (days[i], closing_price[i]))
price_avg = np.zeros(5)
for i in range(1,6):
index = np.where( days == i )
price = np.take(closing_price,index)
avg = np.mean(price)
price_avg[i-1] = avg
print('星期', i, '的平均收盘价是:', price_avg[i-1])
```
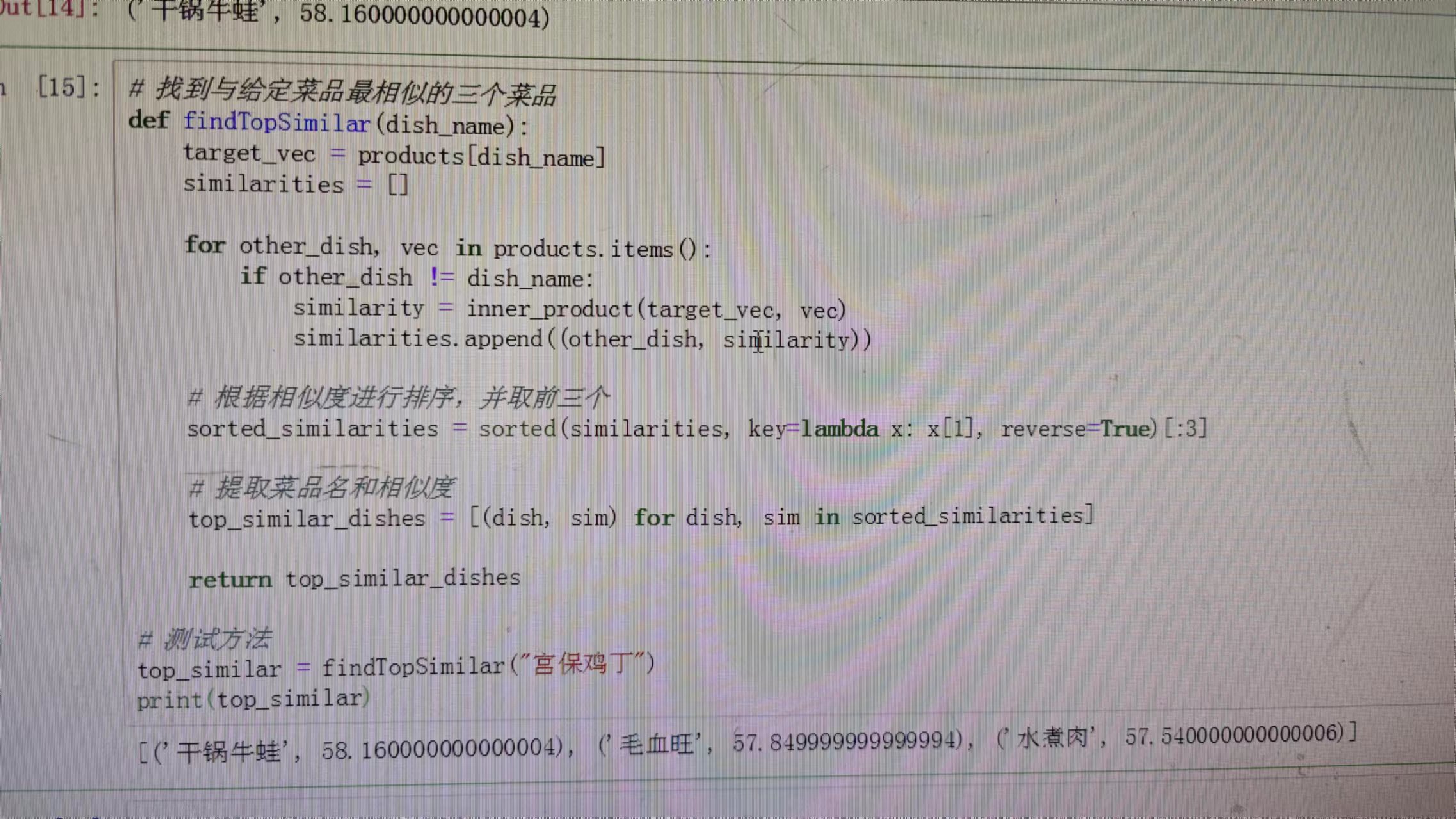
## 相似度计算练习——菜品推荐
```
import numpy as np
# 每道菜有4个特征(辣度、甜度、油腻度、咸度)
products = {
'锅包肉': np.array([2.0, 4.5, 4.9,3.5]),
'毛血旺': np.array([4.5, 2.0, 4.5,4.6]),
'宫保鸡丁': np.array([3.8, 4.0, 3.7,3.5]),
'水煮肉': np.array([4.3, 2.2, 4.5,4.5]),
# ... 可以添加更多商品
}
# 计算两个向量(商品)之间的内积
def inner_product(vec1, vec2):
return np.dot(vec1, vec2)
#找出相速度最高的菜
def findSimilar(x):
# 获取给定菜品的特征向量
target_vec = products[x]
# 初始化最大相似度和最相似菜品
max_similarity = 0.0
most_similar_dish = None
# 遍历所有菜品,计算与给定菜品的内积
for dish, vec in products.items():
if dish != x: # 排除自身
similarity = inner_product(target_vec, vec)
# 如果当前内积大于之前的最大相似度,则更新最大相似度和最相似菜品
if similarity > max_similarity:
max_similarity = similarity
most_similar_dish = dish
# 返回最相似菜品和相似度
return most_similar_dish, max_similarity
```