>[success] # .git 文件
1. 初始化一个本地`git init`仓库,找到`.git` 目录如图

其中`Git objects`是`git`的实际存储数据
* 第一次初始化的 object 文件打开

2. 开始创建文件信息并且通过 `git add` 放入暂存区
~~~
echo '111' > a.txt
echo '222' > b.txt
~~~
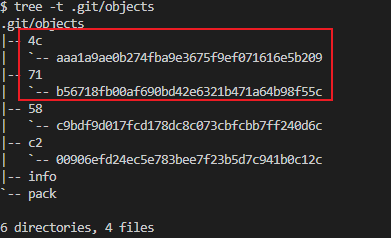
* 将 `a.txt` 和 `b.txt` 放入执行`git add` 放入暂存区后结构目录,多出两个文件 `58` 和`c2`

* 通过 tree 指令查看(tree 指令安装参考集成Tree 指令章节),`tree .git/objects`

如果直接查看 `58` 和`c2` 中两个文件发现是个一串乱码,这是因为Git将信息压缩成二进制文件,`cat .git/objects/58/c9bdf9d017fcd178dc8c073cbfcbb7ff240d6c `

3. `git `提供了相应指令专门用来查看这种文件,`git cat-file [-t] [-p]`,`-t`可以查看object的类型,`-p`可以查看object储存的具体内容
* `git cat-file -t 58c9` `58c9` 文件夹加文件名(文件名可以取前几位即可),类型是一个`blob`类型
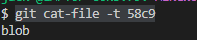
* `git cat-file -p 58c9` 查看加密信息实际内容

**blob类型**,它只**储存的是一个文件的内容**,不包括**文件名等其他信息**。然后将这些**信息经过SHA1哈希算法得到对应的哈希值**,也就是说`58c9bdf9d017fcd178dc8c073cbfcbb7ff240d6c` 现在对应是一个文本内容
4. 将暂存区内容提交到 `git commit -m 'c'`, 执行完成后会多出两个文件

* `tree -t .git/objects`
`git cat-file [-t] [-p]`查看两个文件中任意一个类型和内容
* `git cat-file -t 4caa` 打印结果是一个 `tree` 类型文件

* `git cat-file -p 4caa`,查看加密信息

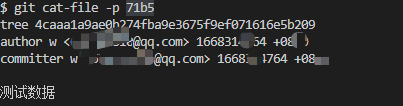
* `git cat-file -t 71b5` 打印结果是一个 `commit` 类型文件1

* `git cat-file -p 71b5`,查看加密信息
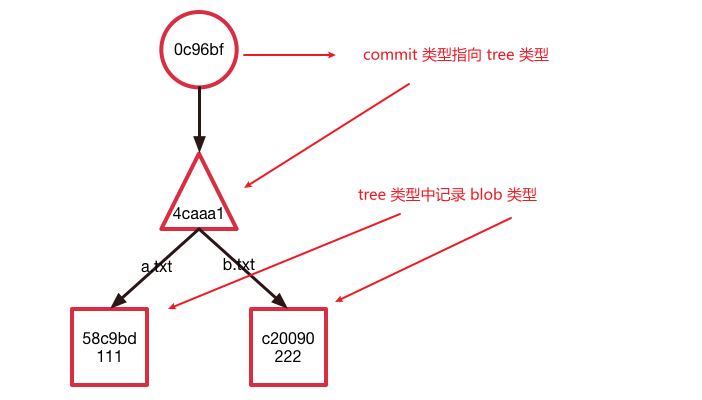
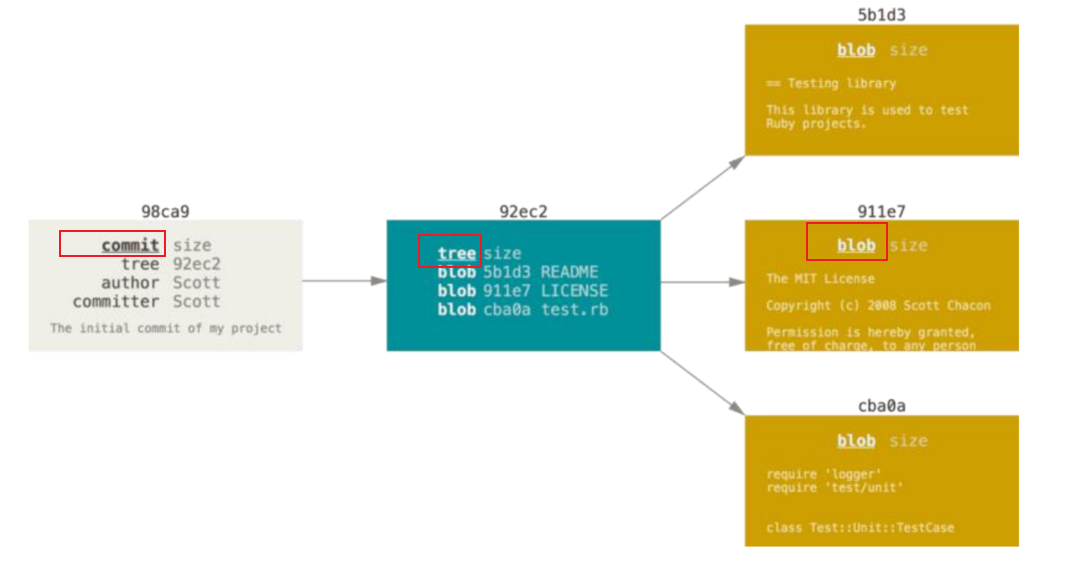
**tree类型**它将当前的目录结构打了一个快照。从它储存的内容来看可以发现它储存了一个目录结构(类似于文件夹),以及每一个文件(或者子文件夹)的权限、类型、对应的身份证(SHA1值)、以及文件名
**commit类型**,它储存的是一个提交的信息,包括对应目录结构的快照tree的哈希值,上一个提交的哈希值(这里由于是第一个提交,所以没有父节点。在一个merge提交中还会出现多个父节点),提交的作者以及提交的具体时间,最后是该提交的信息
* [图片来自](https://www.lzane.com/tech/git-internal/),因此可能和上面操作效果有出入
>[danger] ##### 多几次文件修改
1. 现在继续执行`echo '333' >> a.txt` ,并将文件执行一次完整流程 `git add` 和 `git commit`
2. 执行 `git log --graph` 打印一个日志树,可以看到日志树记录的都是 `commit` 类型的`id`
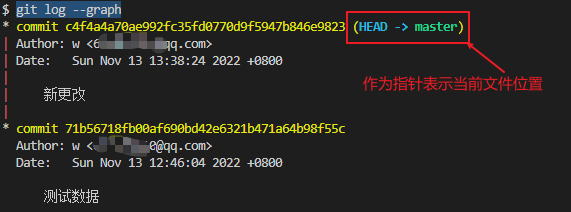
* 可以通过 执行 `git cat-file -t c4f4` 来确认文件类型

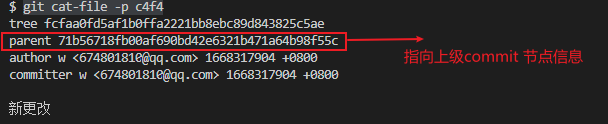
* 执行 `git cat-file -p c4f4` 查看 `commit `类型中具体内容
* 执行`git cat-file -p fcfa` 查看 `c4f4` 指向当前 `tree `类型文件信息

因为本次之更改 `a.txt` 信息,会发现`a.txt` 储存的 `blob` 类型记录值发生了更改(从`58c9bdf9d017fcd178dc8c073cbfcbb7ff240d6c`变`f39c1520a7dee8f5610920364b6faba45b01bfd0`),相对没有进行更改的`b.txt ` `blob` 类型记录值没有改变(`c200906efd24ec5e783bee7f23b5d7c941b0c12c`)
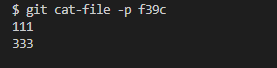
* 执行`git cat-file -p f39c` 查看 修改后`a.txt` 内容,虽然只在 `a.txt` 文件内追加了 `333` 这个内容但可以看到之前`111` 也在本次文件中
Git储存的是全新的文件快照,而不是文件的变更记录。也就是说,就算你只是在文件中添加一行,Git也会新建一个全新的blob object,虽然这样会浪费空间但是checkout一个commit,或对比两个commit之间的差异。如果Git储存的是问卷的变更部分,那么为了拿到一个commit的内容,Git都只能从第一个commit开始,然后一直计算变更,直到目标commit,这会花费很长时间。而相反,Git采用的储存全新文件快照的方法能使这个操作变得很快,直接从快照里面拿取内容就行了
*****
* 形成一个图结构`Git`中的文件内容存储成`blob`(要注意是内容,不是文件。文件的名字和模式不存储在`blob`。因此如果两个文件内容相同,则只会存储一份`blob`)

>[danger] ##### 其他问题
**为什么要把文件的权限和文件名储存在tree object里面而不是blob object呢?**
想象一下修改一个文件的命名。
如果将文件名保存在blob里面,那么Git只能多复制一份原始内容形成一个新的blob object。而Git的实现方法只需要创建一个新的tree object将对应的文件名更改成新的即可,原本的blob object可以复用,节约了空间。
*****
**Git怎么保证历史记录不可篡改**
通过SHA1哈希算法和哈系树来保证。假设你偷偷修改了历史变更记录上一个文件的内容,那么这个问卷的blob object的SHA1哈希值就变了,与之相关的tree object的SHA1也需要改变,commit的SHA1也要变,这个commit之后的所有commit SHA1值也要跟着改变。又由于Git是分布式系统,即所有人都有一份完整历史的Git仓库,所以所有人都能很轻松的发现存在问题。
*****
`Git`中的文件内容存储成`blob`(要注意是内容,不是文件。文件的名字和模式不存储在`blob`。因此如果两个文件内容相同,则只会存储一份`blob`)
*****
`Git`中的文件夹对应为`tree`。`Tree`中含有这个`tree`包含的`blob`和`tree`的名字,模式,类型和`SHA`等信息
*****
`Commit`非常简单,只是指向了一个`tree`,并且包含了作者,提交者,提交信息,和所有的直属`parent commit`
>[info] ## 参考来源
[这才是真正的GIT——GIT内部原理](https://www.lzane.com/tech/git-internal/)
[ Git object 类型笔记](https://nanxiao.me/git-object-type-note/)
