
[TOC]
## **1.Scrapy框架**
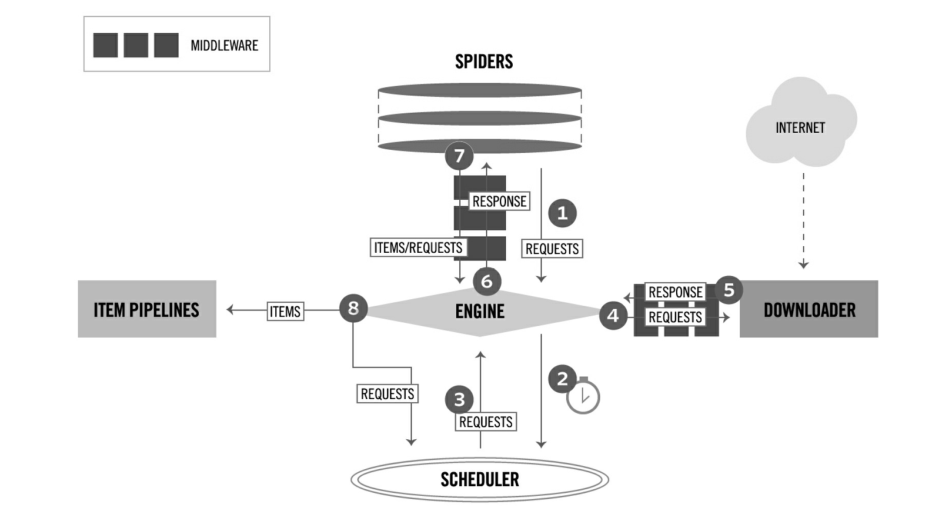
**ENGINE** 引擎,框架的核心,控制其他组件协同工作。
**SCHEDULER** 调度器,负责对SPIDER提交的下载请求进行调度
**DOWNLOADER** 下载器,负责下载页面
**SPIDER** 爬虫,负责提取页面中的数据,并产生新的请求
**MIDDLEWARE** 中间件,负责对Request对象和Response对象进行处理
**ITEM PIPELINE** 数据管道,负责对爬取到的数据进行处理
## **2.安装**
```
pip install scrapy
# 检查安装是否成功
scrapy
```
## **3.基本使用**
### **3.1.创建项目**
```
scrapy startproject example
```
目录结构:
### **3.2.实现爬虫**
在`spiders`目录下创建文件如`books_spider.py`。
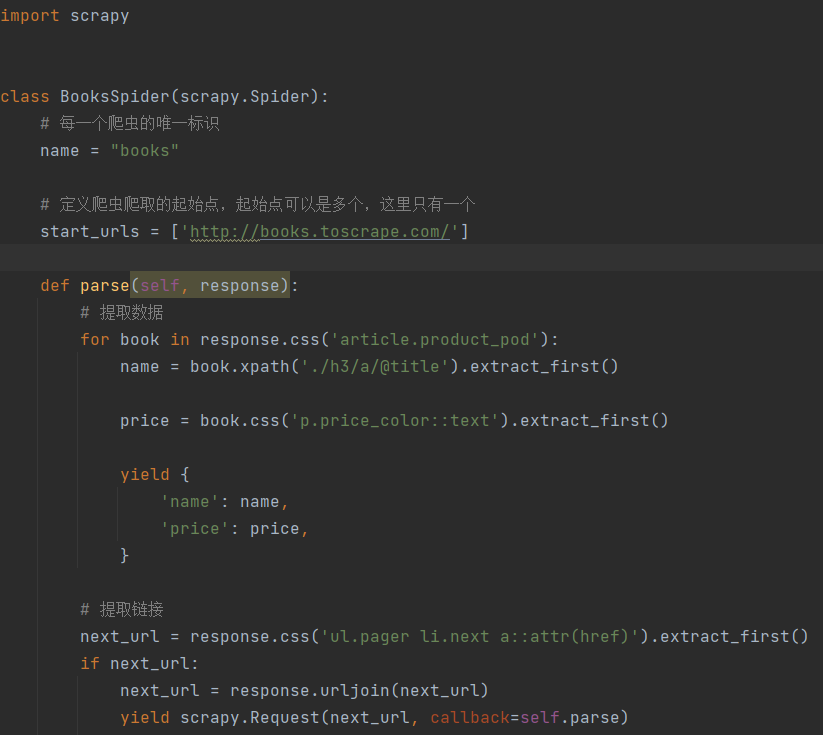
* name:一个项目中有多个爬虫,name属性是唯一标识;
* start_urls:爬虫的起始页面;
* parse:当一个页面下载完成后,Scrapy会回调一个指定的解析函数来解析页面,
通常完成两个任务:提取数据和提取链接。
### **3.3.运行爬虫**
```
scrapy crawl books -o books.csv
```
## **4.编写Spider**
### **4.1.继承scrapy.Spider**
```
import scrapy
class BookSpider(scrapy.Spider):
...
```
Spider基类实现了供Scrapy引擎调用的接口,供用户使用的工具函数,以及供用户访问的属性。
### **4.2.Spider命名**
```
import scrapy
class BookSpider(scrapy.Spider):
name = "books"
...
```
`name`属性来区分的唯一标识。
### **4.3.设置爬虫起点**
```
import scrapy
class BookSpider(scrapy.Spider):
name = "books"
start_urls = ['http://books.toscrape.com/']
...
```
`start_urls`通常为一个列表,里面放置的是爬虫起点的url。
### **4.4.页面解析**
页面解析函数就是构造Request对象时通过callback参数指定的回调函数。
一般完成两个工作:使用选择器提取数据,将数据封装提交个Scrapy引擎;使用选择器或者LinkExtractor提取链接。
## **5.Selector提取数据**
### **5.1.创建对象**
Selector类的实现位于scrapy.selector模块。
```
from scrapy.selector import Selector
text = '''
<html>
...
...
</html>
'''
selector = Selector(text=text)
```
也可以使用Response对象构造Selector对象,传递给Selector构造器方法的response参数。
```
from scrapy.selector import Selector
from scrapy.http import HtmlResponse
body = '''
<html>
...
...
</html>
'''
response = HtmlResponse(url='http://****.com', body=body)
selector = Selector(response=response)
```
### **5.2.筛选数据**
使用xpath方法或者css方法,返回一个SelectorList对象,可以使用for语句来迭代。
```
selector_list = selector.xpath('//h1')
for sel in selector_list:
print(sel.xpath('./text()'))
```
### **5.3.提取数据**
调用Selector或SelectorList对象可用以下方法来提取数据:
* extract() 返回一个列表
* re() 返回指定内容
* extract_first() (SelectorList专有) 返回第一个结果
* re_first() (SelectorList专有) 返回第一个结果
## **6.XPath语法**
XPath即XML路径语言(XML Path Language)
xml文档的节点有以下几种类型:
* **根节点** 整个文档的根
* **元素节点** html、body、div、p、a
* **属性节点** href
* **文本节点** Hello World
节点之间的关系有父子、兄弟、祖先后代。
**基础语法**
| 表达式 | 描述 |
| --- | --- |
| / | 选中文档的根(root) |
| . |选中当前节点 |
| .. | 选中当前节点的父节点 |
| E | 选中子节点中所有E元素节点 |
| //E | 选中后代节点中所有E元素节点 |
| * | 选中所有元素子节点 |
| text() | 选中所有文本子节点 |
| @ATTR | 选中名为ATTR的属性节点 |
| @* | 选中所有属性节点 |
| [谓语] | 用来查找某个特定的节点或者包含某个特定的节点 |
## **7.CSS选择器**
**基本语法**
| 表达式 | 描述 | 例子 |
| --- | --- | --- |
| * | 选中所有元素 | * |
| E |选中E元素 | p |
| E1,E2 | 选中E1,E2 | div,pre |
| E1 E2 | 选中E1后代中的E2 | div p |
| E1>E2 | 选中E1子元素中的E2 | div>p |
| E1+E2 | 选中E1兄弟元素中E2 | p+strong |
| .CLASS | 选中class属性包含CLASS的元素 | .info |
| #ID | 选中id属性包含ID的元素| #main |
| [ATTR] | 选中包含ATTR属性的元素 | [href] |
| [ATTR=VALUE] | 选中包含ATTR属性且值为VALUE的元素 | [method=post] |
|[ATTR~=VALUE] | 选中包含ATTR属性且值包含VALUE的元素 | [class~=clearfix] |
| E:nth-child(n) E:nth-last-child(n) | 选中E元素,且该元素必须是其父元素的(倒数)第n个子元素。 | a:nth-child(1) |
| E:first-child E:last-child | 选中E元素,其该元素必须是其父元素的(倒数) 第一个子元素 | a:first-child |
| E:empty | 选中没有子元素的E元素 | div:empty |
| E::text | 选中E元素的文本节点(Text Node) | p::text |
## **8.Item封装数据**
### **8.1.Item和Field**
* Item基类
自定义数据类的基类
* Field类
用来描述自定义数据类包含哪些字段
- Golang
- 基础知识
- 基本数据类型
- 运算符
- 变量&常量
- 流程控制
- 数组
- 切片
- string操作
- Map及实现原理
- Go其他
- CLI命令
- Golang内置类型和函数
- init函数和main函数
- 网络编程
- 互联网协议
- socket编程
- 单元测试
- 并发编程
- channel
- 优雅地关闭channel
- Mutex
- GMP原理与调度
- Go Web
- HTTP Server
- gin框架
- 快速入门
- HTML渲染
- JSONP
- Multipart/Urlencoded绑定
- PureJSON
- gin路由
- beego框架
- Bee工具安装
- 配置模块
- Web模块
- 路由
- 数据操作
- Go操作Mysql数据库
- Go操作redis
- mongo-driver
- sqlx库
- 操作etcd
- msgpack
- 网络爬虫
- 获取页面
- 标准库
- IO操作
- 文件操作
- fmt
- 格式化输出
- flag
- log
- time
- strconv
- template
- os
- sync.Mutex
- Context
- 第三方库
- zap库
- viper
- validator参数校验
- GORM
- 基础
- CRUD接口
- INI
- GoFrame
- 快速开始
- 微服务
- go-kit
- gRPC
- Protocol Buffers 语法指南
- go-zero
- 相关名词解释
- 数据结构和算法
- 基础知识
- 链表
- Golang GUI
- fyne基础
- 显示时间
- RabbitMQ-Go
- centos7 安装rabbitmq-server
- RabbitMQ介绍
- 工作队列
- Go设计模式
- 设计模式的分类
- 简单工厂模式
- golang自举编译
- 了解sync.Once
- 知识碎片
- 常见问题
- 开源项目
- Python
- Anaconda
- 介绍、使用教程
- Python基础知识
- Python之禅
- 变量和类型
- 流程控制
- Python运维
- Python内置工具
- 命令行工具
- 包管理工具pip
- 小爬虫笔记
- I/O操作
- requests库
- requests基本使用
- BeautifulSoup库
- BeautifulSoup基本使用
- Scrapy框架
- 数据可视化
- Django
- Django起步
- OpenCV
- OpenCV入门
- PHP笔记
- PHP基础语法
- 前端
- HTML
- CSS
- CSS权重计算
- Javascript
- 基础
- JS基础知识
- 监听事件
- 字符串操作
- 数组操作
- 输入输出
- 定时器
- 样式操作
- 获取url参数
- Typescript
- Pick 与 Omit TS内置类型
- Vue.js
- Vue.js介绍
- Vue.js基础
- Vue指令
- v-model
- v-for
- 指令修饰符
- Q&A
- 命令
- Vue3
- node.js
- node.js基础
- npm遇到的问题
- 相关工具安装
- nvm使用教程
- 工程化webpack
- 遇到的问题
- Linux
- Linux基础
- 符号链接
- Shell
- 脚本执行方式
- 数据的输入输出
- 脚本执行中的问题
- tcpdump
- 正则表达式
- Elasticsearch
- Docker
- Docker的基础概念与操作
- Docker 安装
- 容器技术原理
- Docker核心概念
- Docker基本操作
- 镜像相关操作
- 容器相关操作
- 镜像加速器
- Dockerfile
- COPY复制文件
- Docker所遇问题
- ansible
- ansible入门
- k8s
- 安装工具
- kubectl
- Git
- gitlab
- gitlab备份与恢复
- gitlab基本使用
- git使用
- git常用命令
- git提交问题
- git提交规范
- 数据库
- MySQL
- MySQL介绍
- mariadb安装
- 主主复制
- 数据库问题集结
- 开启binlog
- MySQL常用命令
- SQL总结
- MySQL性能优化系列
- 第一章 初始化安装和简单安全加固
- 第二章 认识performance_schema
- 第三章 MySQL体系结构
- MySQL配置模板
- Redis
- Redis简单使用
- Redis常见问题
- Redis集群
- Redis Cluster概述
- 数据分布
- 搭建集群
- MongoDB
- mongodb分片
- MongoDB分片集群设置密码验证
- TiDB
- 单机模拟部署生产环境集群
- 服务器
- CentOS
- 配置阿里云的yum源和epel源
- centos7 实现NFS文件共享
- rsync
- centos7 源码编译rsync
- rsync实现文件同步
- 添加删除swap分区
- 清除buff/cache
- 配置ntp时间同步
- centos7安装pip
- centos7虚拟机启动报xfs错误
- centos7常用命令
- centos7安装mysql
- centos7安装python3.x
- centos7升级gcc、g++
- centos7安装nginx
- centos7部署Nexus
- centos7离线安装python3
- centos7.6编译mariadb10.5.22
- CentOS8
- 银河麒麟V4
- nginx编译
- 银河麒麟V10_x86
- 安装VNC
- 单用户模式
- UOS
- 配置本地apt源
- apt安装vnc-server
- UOS单用户模式
- UOS创建自启动脚本
- 源码编译
- oniguruma编译
- Proxmox VE
- PVE基本使用
- PVE故障
- KVM
- KVM相关命令
- 银河麒麟V10_x86安装kvm
- UOS_arm64安装kvm
- yum、rpm、apt
- dpkg、apt-get、yum和rpm的区别
- rpm打包
- yum相关问题
- 内建银河麒麟的apt源
- 其他软件
- JuiceFS
- nacos
- 常见命令
- 硬盘分区
- Linux常见问题
- Ubuntu搭建arm64 qt 开发环境
- 测试
- sysbench
- 其他
- Cloc代码统计工具
- onlyoffice 在线文档编辑
- onlyoffice添加中文字体
- 遇到的问题
- 网络通信协议
- 部署相关记录
- Vmware workstation虚拟机迁移到PVE指南
- 小操作