
[TOC]
# 时间分片
## 使用定时器
在 JS 的`Event Loop`中,当JS引擎所管理的执行栈中的事件以及所有微任务事件全部执行完后,才会触发渲染线程对页面进行渲染。
页面的卡顿是由于同时渲染大量DOM所引起的,所以我们考虑将渲染过程分批进行。
<br>
## requestAnimationFrame
### setTimeout 和闪屏现象
* `setTimeout`的执行时间并不是确定的。在JS中,`setTimeout`任务被放进事件队列中,只有主线程执行完才会去检查事件队列中的任务是否需要执行,因此`setTimeout`的实际执行时间可能会比其设定的时间晚一些。
* 刷新频率受屏幕分辨率和屏幕尺寸的影响,因此不同设备的刷新频率可能会不同,而`setTimeout`只能设置一个固定时间间隔,这个时间不一定和屏幕的刷新时间相同。
以上两种情况都会导致setTimeout的执行步调和屏幕的刷新步调不一致。
在`setTimeout`中对dom进行操作,必须要等到屏幕下次绘制时才能更新到屏幕上,如果两者步调不一致,就可能导致中间某一帧的操作被跨越过去,而直接更新下一帧的元素,从而导致丢帧现象。
<br>
### 使用 requestAnimationFrame
与`setTimeout`相比,`requestAnimationFrame`最大的优势是由系统来决定回调函数的执行时机。
如果屏幕刷新率是60Hz,那么回调函数就每16.7ms被执行一次,如果刷新率是75Hz,那么这个时间间隔就变成了1000/75=13.3ms,换句话说就是,`requestAnimationFrame`的步伐跟着系统的刷新步伐走。它能保证回调函数在屏幕每一次的刷新间隔中只被执行一次,这样就不会引起丢帧现象。
<br>
## DocumentFragment
`DocumentFragments`是DOM节点,但并不是DOM树的一部分,可以认为是存在内存中的,所以将子元素插入到文档片段时不会引起页面回流。
<br>
## 最终代码
~~~
<ul id="container"></ul>
~~~
~~~
//需要插入的容器
let ul = document.getElementById('container');
// 插入十万条数据
let total = 100000;
// 一次插入 20 条
let once = 20;
//总页数
let page = total/once
//每条记录的索引
let index = 0;
//循环加载数据
function loop(curTotal,curIndex){
if(curTotal <= 0){
return false;
}
//每页多少条
let pageCount = Math.min(curTotal , once);
window.requestAnimationFrame(function(){
let fragment = document.createDocumentFragment();
for(let i = 0; i < pageCount; i++){
let li = document.createElement('li');
li.innerText = curIndex + i + ' : ' + ~~(Math.random() * total)
fragment.appendChild(li)
}
ul.appendChild(fragment)
loop(curTotal - pageCount,curIndex + pageCount)
})
}
loop(total,index);
~~~
<br>
<br>
# worker
## 什么是worker
~~~
运行者 Worker 接口是Web Workers API的一部分,代表一个后台任务,
它容易被创建并向创建者发回消息。创建一个运行者只要简单的调用Worker()构造函数,指定一个脚本,在工作线程中执行。(引自MDN)
~~~
看概念可能有点枯燥,通俗点讲就是:因为js是单线程运行的,在遇到一些需要处理大量数据的js时,可能会阻塞页面的加载,造成页面的假死。这时我们可以使用worker来开辟一个独立于主线程的子线程来进行哪些大量运算。这样就不会造成页面卡死。也说明 worker可以用来解决大量运算是造成页面卡死的问题。
<br>
<br>
## 语法
### 创建 Web Workers
~~~
const worker=new Worker(aURL, options)
~~~
它有两个参数:
* aURL(必须)是一个DOMString 表示worker 将执行的脚本的URL。它必须遵守同源策略。
* options (可选)它的一个作用就是指定 Worker 的名称,用来区分多个 Worker 线程
<br>
### 收发消息
Web Workers 用来执行异步脚本,只要掌握了它与主线程通信的方式,就可以在指定时机运行异步脚本,并在运行完时将结果传递给主线程。
<br>
### 主线程接收发 Web Workers 消息
~~~text
const worker = new Worker("../src/worker.js");
worker.onmessage = e => {};
worker.postMessage("Marco!");
~~~
每个`worker`实例通过`onmessage`接收消息,通过`postMessage`发送消息。
<br>
### Web Workers 收发主线程消息
~~~text
self.onmessage = e => {};
self.postMessage("Marco!");
~~~
和主线程代码类似,在 Web Workers 代码中,也是`onmessage`接收消息,这个消息来自主线程或者其它 Workers。也可以通过`postMessage`发送消息。
<br>
### 销毁 Web Workers
~~~text
worker.terminate();
~~~
文章内容就这么多,是不是有写太简单了呢!笔者结合自己的使用经验,再补充一些知识。
<br>
<br>
## 使用worker的注意点
<br>
### 1.同源限制
分配给 Worker 线程运行的脚本文件,必须与主线程的脚本文件同源。
<br>
### 2.DOM 限制
Worker 线程所在的全局对象,与主线程不一样,无法读取主线程所在网页的 DOM 对象,也无法使用document、window、parent这些对象。但是,Worker 线程可以navigator对象和location对象。
<br>
### 3.通信联系
Worker 线程和主线程不在同一个上下文环境,它们不能直接通信,必须通过消息完成。
<br>
### 4.脚本限制
Worker 线程不能执行alert()方法和confirm()方法,但可以使用 XMLHttpRequest 对象发出 AJAX 请求。
<br>
### 5.文件限制
Worker 线程无法读取本地文件,即不能打开本机的文件系统(file://),它所加载的脚本,必须来自网络。
<br>
## 优化
### 对象转移(Transferable Objects)
对象转移就是将对象引用零成本转交给 Web Workers 的上下文,而不需要进行结构拷贝。
这里要解释的是,**主线程与 Web Workers 之间的通信,并不是对象引用的传递,而是序列化/反序列化的过程**,当对象非常庞大时,序列化和反序列化都会消耗大量计算资源,降低运行速度。
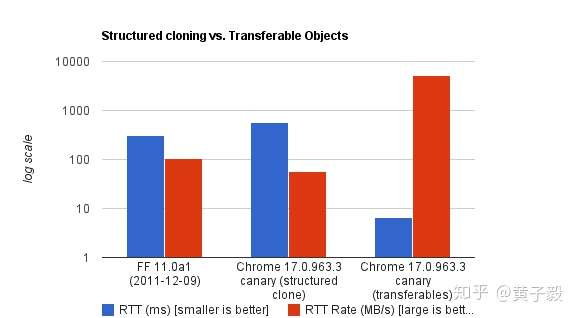
上面的图充分证明了,大对象传递,使用对象转移各项指标都优于结构拷贝。
对象转移使用方式很简单,给`postMessage`增加一个参数,把对象引用传过去即可:
~~~text
var ab = new ArrayBuffer(1);
worker.postMessage(ab, [ab]);
~~~
浏览器兼容性也不错:Currently Chrome 17+, Firefox, Opera, Safari, IE10+。更具体内容,可以看[Transferable Objects: Lightning Fast!](https://link.zhihu.com/?target=https%3A//developers.google.com/web/updates/2011/12/Transferable-Objects-Lightning-Fast)。
> 需要注意的是,对象引用转移后,原先上下文就无法访问此对象了,需要在 Web Workers 再次将对象还原到主线程上下文后,主线程才能正常访问被转交的对象。
### 如何不用 JS 文件创建 Web Workers
Web Workers 优势这么大,但用起来需要在同域下创建一个 JS 文件实在不方便,尤其在前后端分离做的比较彻底的团队,前端团队能控制的仅仅是一个 JS 文件。那么下面给出几个不用 JS 文件,就创建 Web Workers 的方法:
### webpack 插件 - worker-loader
[worker-loader](https://link.zhihu.com/?target=https%3A//github.com/webpack-contrib/worker-loader)是一个 webpack 插件,可以将一个普通 JS 文件的全部依赖提取后打包并替换调用处,以 Blob 形式内联在源码中。
~~~text
import Worker from "worker-loader!./file.worker.js";
const worker = new Worker();
~~~
上述代码的魔术在于,转化成下面的方式执行:
~~~text
const blob = new Blob([codeFromFileWorker], { type: "application/javascript" });
const worker = new Worker(URL.createObjectURL(blob));
~~~
### Blob URL
第二种方式由第一种方式自然带出:如果不想用 webpack 插件,那自己通过 Blob 的方式创建也可以:
~~~text
const code = `
importScripts('https://xxx.com/xxx.js');
self.onmessage = e => {};
`;
const blob = new Blob([code], { type: "application/javascript" });
const worker = new Worker(URL.createObjectURL(blob));
~~~
看上去代码更轻量一些,不过问题是当遇到复杂依赖时,如果不能把依赖都转化为脚本通过`importScripts`方式引用,就无法访问到主线程环境中的包。如果真的遇到了这个问题,可以用第一种 webpack 插件的方式解决,这个插件会自动把文件所有依赖都打包进源码。
### 管理 postMessage 队列
为什么 postMessage 会形成队列,为什么要管理它?
首先在 Web Workers 架构设计上就必须做成队列,因为调用`postMessage`时,对应的 Web Workers 不一定完成了初始化,所以浏览器底层必须管理一个队列,在 Web Workers 初始化完毕时,依次消费,这样才能确保任何时候发出的`postMessage`都能被 Web Workers 接收到。
其次,为什么要手动维护这个队列,原因可能取决于如下几点:
* 业务原因,前面的`postMessage`还没来得及消费,就不要发送新的消息,或者丢弃新的消息,这时候需要通过双向通信拿到 Web Workers 的执行结果回执,手动控制队列。
* 性能原因,一般 Web Workers 都会被用来执行耗时的同步运算,如果运算时间比较长,那短期塞入多个消息队列是没有意义的。
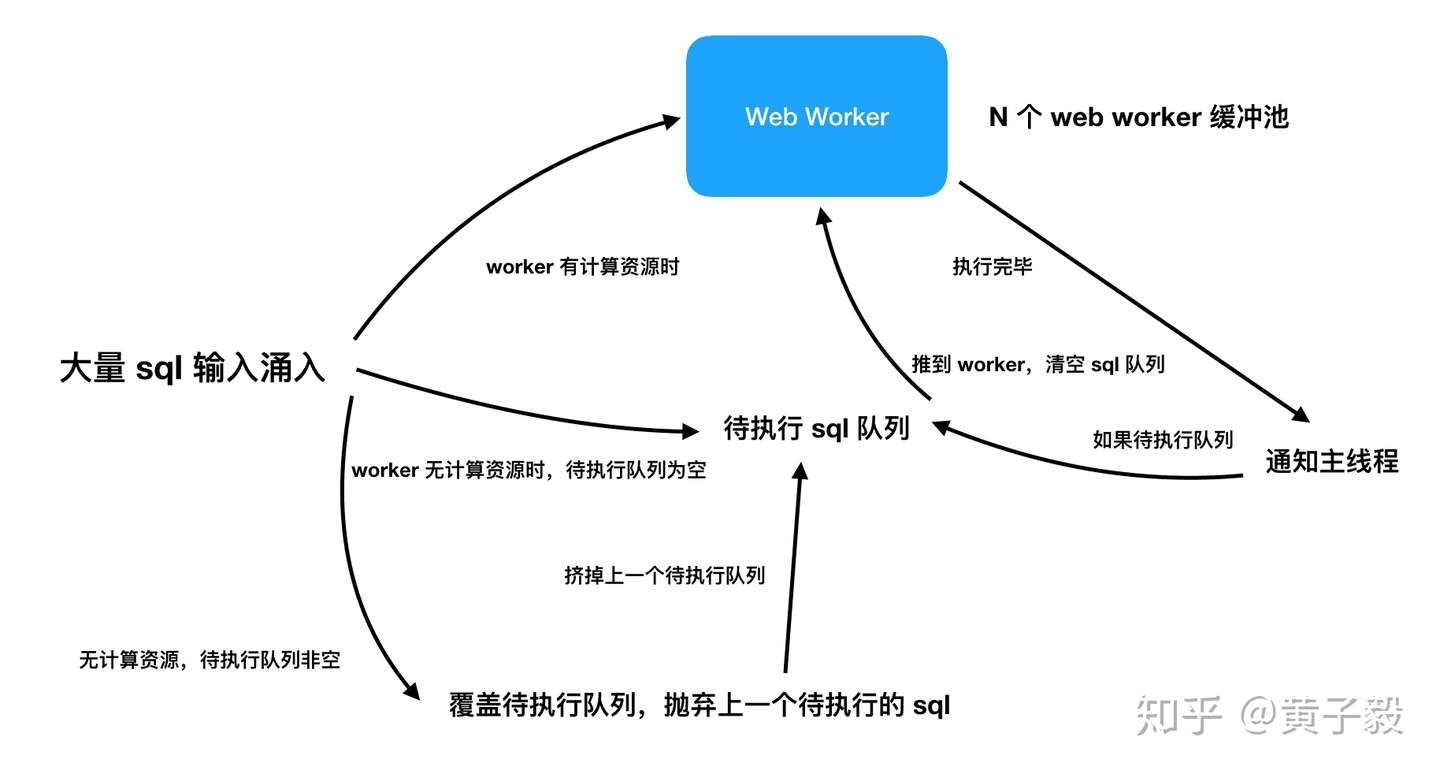
如上图所示,对于每次用户输入都要进行的 SQL Parser 很耗时,及时放在 Web Workers 也可能导致将 Workers 撑爆到无响应,这是不仅要使用多 Workers 缓冲池,还要对待执行队列进行过滤,因为用户永远只关心最后一次输入的 Parser 结果。
由于 Web Workers 运算被卡住时,除了销毁 Worker 没有别的办法,而销毁 Worker 的成本比较高,不能对每一个用户输入都销毁并新建 Web Workers,所以利用 Workers 缓冲池,当缓冲池满了,新的消费队列又进来的时候,可以销毁全部 Workers 缓冲池,换一批新缓冲池重新消费用户输入。
<br>
<br>
# 虚拟列表
https://juejin.cn/post/6844903982742110216#heading-5
<br>
<br>
# 参考资料
* [「中高级前端」高性能渲染十万条数据(时间分片)](https://juejin.im/post/5d76f469f265da039a28aff7)
* [ 聊聊前端开发中的长列表](https://zhuanlan.zhihu.com/p/26022258)
* [再谈前端虚拟列表的实现](https://zhuanlan.zhihu.com/p/34585166)
- 第一部分 HTML
- meta
- meta标签
- HTML5
- 2.1 语义
- 2.2 通信
- 2.3 离线&存储
- 2.4 多媒体
- 2.5 3D,图像&效果
- 2.6 性能&集成
- 2.7 设备访问
- SEO
- Canvas
- 压缩图片
- 制作圆角矩形
- 全局属性
- 第二部分 CSS
- CSS原理
- 层叠上下文(stacking context)
- 外边距合并
- 块状格式化上下文(BFC)
- 盒模型
- important
- 样式继承
- 层叠
- 属性值处理流程
- 分辨率
- 视口
- CSS API
- grid(未完成)
- flex
- 选择器
- 3D
- Matrix
- AT规则
- line-height 和 vertical-align
- CSS技术
- 居中
- 响应式布局
- 兼容性
- 移动端适配方案
- CSS应用
- CSS Modules(未完成)
- 分层
- 面向对象CSS(未完成)
- 布局
- 三列布局
- 单列等宽,其他多列自适应均匀
- 多列等高
- 圣杯布局
- 双飞翼布局
- 瀑布流
- 1px问题
- 适配iPhoneX
- 横屏适配
- 图片模糊问题
- stylelint
- 第三部分 JavaScript
- JavaScript原理
- 内存空间
- 作用域
- 执行上下文栈
- 变量对象
- 作用域链
- this
- 类型转换
- 闭包(未完成)
- 原型、面向对象
- class和extend
- 继承
- new
- DOM
- Event Loop
- 垃圾回收机制
- 内存泄漏
- 数值存储
- 连等赋值
- 基本类型
- 堆栈溢出
- JavaScriptAPI
- document.referrer
- Promise(未完成)
- Object.create
- 遍历对象属性
- 宽度、高度
- performance
- 位运算
- tostring( ) 与 valueOf( )方法
- JavaScript技术
- 错误
- 异常处理
- 存储
- Cookie与Session
- ES6(未完成)
- Babel转码
- let和const命令
- 变量的解构赋值
- 字符串的扩展
- 正则的扩展
- 数值的扩展
- 数组的扩展
- 函数的扩展
- 对象的扩展
- Symbol
- Set 和 Map 数据结构
- proxy
- Reflect
- module
- AJAX
- ES5
- 严格模式
- JSON
- 数组方法
- 对象方法
- 函数方法
- 服务端推送(未完成)
- JavaScript应用
- 复杂判断
- 3D 全景图
- 重载
- 上传(未完成)
- 上传方式
- 文件格式
- 渲染大量数据
- 图片裁剪
- 斐波那契数列
- 编码
- 数组去重
- 浅拷贝、深拷贝
- instanceof
- 模拟 new
- 防抖
- 节流
- 数组扁平化
- sleep函数
- 模拟bind
- 柯里化
- 零碎知识点
- 第四部分 进阶
- 计算机原理
- 数据结构(未完成)
- 算法(未完成)
- 排序算法
- 冒泡排序
- 选择排序
- 插入排序
- 快速排序
- 搜索算法
- 动态规划
- 二叉树
- 浏览器
- 浏览器结构
- 浏览器工作原理
- HTML解析
- CSS解析
- 渲染树构建
- 布局(Layout)
- 渲染
- 浏览器输入 URL 后发生了什么
- 跨域
- 缓存机制
- reflow(回流)和repaint(重绘)
- 渲染层合并
- 编译(未完成)
- Babel
- 设计模式(未完成)
- 函数式编程(未完成)
- 正则表达式(未完成)
- 性能
- 性能分析
- 性能指标
- 首屏加载
- 优化
- 浏览器层面
- HTTP层面
- 代码层面
- 构建层面
- 移动端首屏优化
- 服务器层面
- bigpipe
- 构建工具
- Gulp
- webpack
- Webpack概念
- Webpack工具
- Webpack优化
- Webpack原理
- 实现loader
- 实现plugin
- tapable
- Webpack打包后代码
- rollup.js
- parcel
- 模块化
- ESM
- 安全
- XSS
- CSRF
- 点击劫持
- 中间人攻击
- 密码存储
- 测试(未完成)
- 单元测试
- E2E测试
- 框架测试
- 样式回归测试
- 异步测试
- 自动化测试
- PWA
- PWA官网
- web app manifest
- service worker
- app install banners
- 调试PWA
- PWA教程
- 框架
- MVVM原理
- Vue
- Vue 饿了么整理
- 样式
- 技巧
- Vue音乐播放器
- Vue源码
- Virtual Dom
- computed原理
- 数组绑定原理
- 双向绑定
- nextTick
- keep-alive
- 导航守卫
- 组件通信
- React
- Diff 算法
- Fiber 原理
- batchUpdate
- React 生命周期
- Redux
- 动画(未完成)
- 异常监控、收集(未完成)
- 数据采集
- Sentry
- 贝塞尔曲线
- 视频
- 服务端渲染
- 服务端渲染的利与弊
- Vue SSR
- React SSR
- 客户端
- 离线包
- 第五部分 网络
- 五层协议
- TCP
- UDP
- HTTP
- 方法
- 首部
- 状态码
- 持久连接
- TLS
- content-type
- Redirect
- CSP
- 请求流程
- HTTP/2 及 HTTP/3
- CDN
- DNS
- HTTPDNS
- 第六部分 服务端
- Linux
- Linux命令
- 权限
- XAMPP
- Node.js
- 安装
- Node模块化
- 设置环境变量
- Node的event loop
- 进程
- 全局对象
- 异步IO与事件驱动
- 文件系统
- Node错误处理
- koa
- koa-compose
- koa-router
- Nginx
- Nginx配置文件
- 代理服务
- 负载均衡
- 获取用户IP
- 解决跨域
- 适配PC与移动环境
- 简单的访问限制
- 页面内容修改
- 图片处理
- 合并请求
- PM2
- MongoDB
- MySQL
- 常用MySql命令
- 自动化(未完成)
- docker
- 创建CLI
- 持续集成
- 持续交付
- 持续部署
- Jenkins
- 部署与发布
- 远程登录服务器
- 增强服务器安全等级
- 搭建 Nodejs 生产环境
- 配置 Nginx 实现反向代理
- 管理域名解析
- 配置 PM2 一键部署
- 发布上线
- 部署HTTPS
- Node 应用
- 爬虫(未完成)
- 例子
- 反爬虫
- 中间件
- body-parser
- connect-redis
- cookie-parser
- cors
- csurf
- express-session
- helmet
- ioredis
- log4js(未完成)
- uuid
- errorhandler
- nodeclub源码
- app.js
- config.js
- 消息队列
- RPC
- 性能优化
- 第七部分 总结
- Web服务器
- 目录结构
- 依赖
- 功能
- 代码片段
- 整理
- 知识清单、博客
- 项目、组件、库
- Node代码
- 面试必考
- 91算法
- 第八部分 工作代码总结
- 样式代码
- 框架代码
- 组件代码
- 功能代码
- 通用代码